Migrating the API to Cloudflare Workers
This is an old blog post that I typed circa 2021 up but never got around to publishing.
It goes into a little detail about how the API was operating before, the architure behind it, and how it operates in Cloudflare now. Read this document as if it is 2020
StopForumSpam started in 2007 and within 6 months we were serving 5,000 requests directly out of MySQL. As demand grew over the next 5 years to levels well beyond what was ever expected, the API underwent several redesigns ending up to where it is now, serving about 400-500 requests per second.
As StopForumSpam grew, so did the need to reduce the request latency and increase its fault tolerance. This is where Cloudflare Workers shines.
The most recent major change as StopForumSpam has seen the API migrate to running in Cloudflare Workers… and here is the story about how it happened, told from the perspective of someone that is anything but a professional developer. I cover how the API has operated for the last several years, how it stored and processed data, how some of the architect had to change to operate in Workers, and the lessons learned.
Workers is a “serverless” platform for executing lightweight javascript on the edge of Cloudflare’s network, in over 140 locations worldwide.
This allows API queries to execute in the closest Cloudflare datacenter to your server instead of requests having to travel the globe as they would with a traditional web server application.
Legacy Architecture
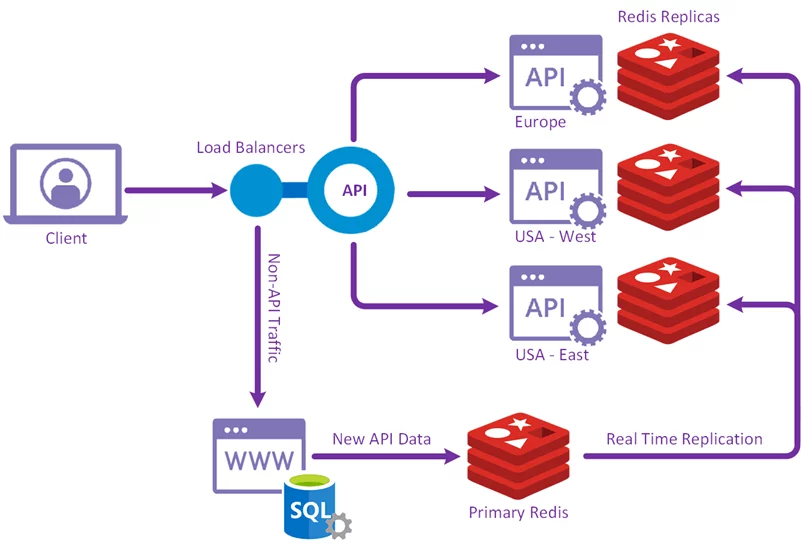
Redis, Redis, and more Redis
At the heart of the API for the last several years is our custom version of Redis. Redis is extendable screaming fast in-memory NoSQL DB with a lightweight data protocol and a robust method for real time replication of data. As records are pushed into Redis, they’re distributed to all the API nodes using its real time replication mechanism.
This puts the data on the API node closest to your server, either in Europe or on each coast of the USA, with requests being routed one of two ways depending on the domain being used for queries. If you used stopforumspam.org then you hit Sucuri's geographic Anycast routing system directly. If you used stopforumspam.com then API requests were routed via a Cloudflare worker to rewrite the host headers before forwarding the request to Sucuri.
The final hop was the Sucuri network sending the request to your closest API servers.
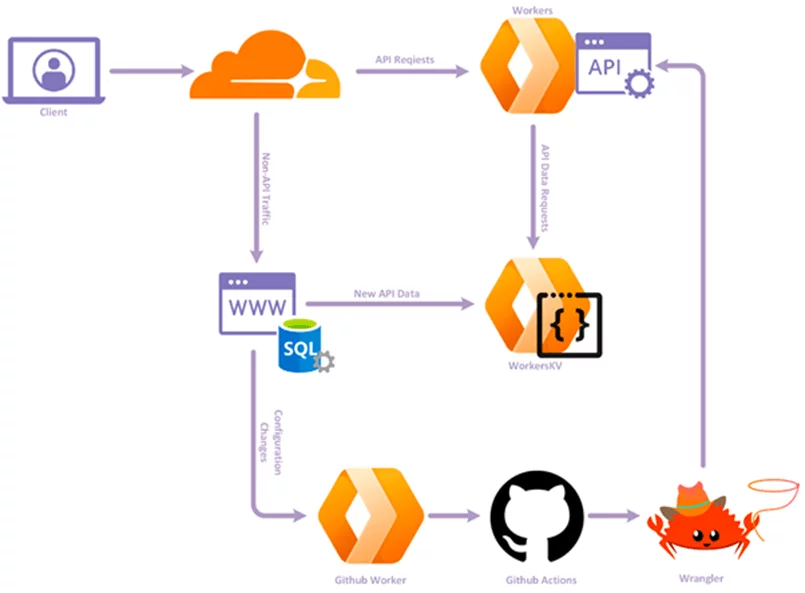
This is where the design changes needed to happen to support the transition to new data structures and methods to access them. In order to discuss the data structure migration, here is how the two data types are structured in Redis.
- API data is inserted into Redis using a hashsets with a key derived from the first two bytes of the record hash and the hash value from the remainder of the hash, up to 64 bits (with some longer values for older legacy data).
The record itself (last seen date, count total, country etc) is built and stored using the PHP function pack format. This use of binary packed hash sets and binary packed data reduces memory usage from 4GB as a primary key strategy, to 250MB which is small enough to run API nodes on cheap VPS servers.
- Extra non-spam related IP data, such as IP to country and IP to ASN data is stored in Redis interval sets which allows you to “stab” at ranges of IP addresses, pulling data for ranges which your IP address falls in.
A small example, adding an email address
md5("spam@spam.com") = ea5036994d8e3d00fe4c9ede36c2d05a
which gives us the key value and field
hash key = "ea50"
hash field = "36994d8e3d00"
and throw in some example record data
packedRecord = "\x83\xa1c\x02\xa1t\xce^\x14|\x18\xa1n\xa2id"
gives the following interaction on insert
> hset "\xea\x50" "\x36\x99\x4d\x8e\x3d\x00" "\x83\xa1c\x02\xa1t\xce^\x14|\x18\xa1n\xa2id" ↲
This uniformly distributes all API data into 65,536 sets of almost equal size.
> hgetall "\xea\x50" ↲
1) "'A\xca\xae\xc4\x0c"
2) "\x82\xa1c\x02\xa1t\xce\]\xba\xf8\xf8"
3) "x\xa8\xb9\x9d\xa5\xcc"
...
156) "\x82\xa1\x01\xa1t\xce\_u\x8e\xe7"
157) "\x15\x1bu\*\x1f\xdb"
158) "\x82\xa1c\x01\xa1t\xce\_wDD"
To check an API request for any particular data, a call to Redis for the hash key and field pair will return a record if one exists, eg
> hget "\xea\x50" "\x36\x99\x4d\x8e\x3d\x00" ↲
1) "\x83\xa1c\x02\xa1t\xce^\x14|\x18\xa1n\xa2id"
The second Redis data structure is used for doing IP to ASN and IP to Country looks up.
Example, for IP to ASN/country (with 202968593 being the integer value for 12.25.14.17)
> istab ip_data 202968593 ↲
1) "7018:us"
This is a very powerful data structure in Redis for this use case, one that is very complex to maintain properly using native Redis commands, especially when IP ranges overlap. Just a note that Interval Sets are not in the main Redis repository as the pull request was rejected.
Migrating to Workers and Workers KV
The first data model change meant taking hash sets from Redis and transforming them into a data structure that works within WorkersKV, a native json datastore. Before any strategy was decided on, it was important to understand the datastore itself.
WorkersKV is an eventually consistent distributed primary key datastore. The simplest way to describe it within the scope of this bit of work is that it's a large datastore located in California somewhere, and when you request data from it then you get from a local cache if it's there, and retrieved from the main datastore if it's not. When you write to it, the data is committed to a cache locally before eventually reaching the main datastore. This takes a second or ten but there is no guarantee of time of this delay.
The underlying way in which WorkersKV transports data meant that data had to be sharded in order to operate the API at the speeds required by clients. By minimizing the record size, we reduce latency and the amount of wasted bandwidth, however reducing the key size too much results in a large number of shards. This introduces the chances of orphaning data and exponentially increases the time to do a WorkersKV data import because of the limit of the number of buckets that can be processed in each Cloudflare API write request.
After slicing up data sets into different key lengths and shard sizes, a mirror of the existing strategy was chosen with the existing 65,536 hash sets, each stored as a json object and stored in WorkersKV as a key based on the first two bytes (four hexadecimal characters) of each shard set, mimicking the Redis hashset strategy.
Cloudflare has a lot of detailed information available about WorkersKV, available at https://blog.cloudflare.com/workers-kv-is-ga/
As memory limitations are no longer as issue in WorkersKV as they were in Redis, full hashes are now used as the record key. Each key is about 12KB in size, or about 3KB max when compressed as it hits the network.
API data now looks like this in WorkersKV - json formatted data
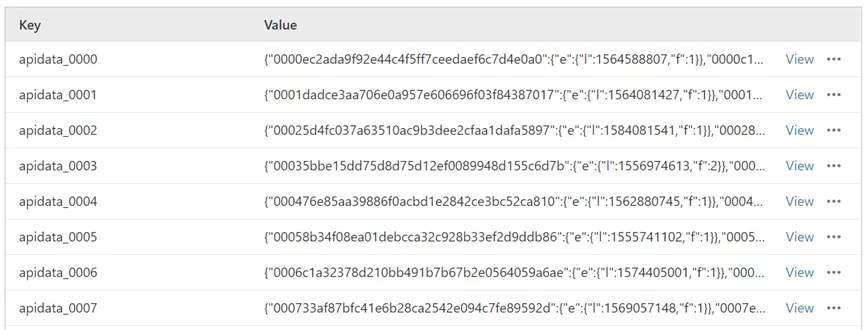
Now the data is structured, there is a problem to avoid any key collisions when submitting data to a non-atomic database when the same keys are updated quickly. Whilst there is no guarantee that old data doesn’t overwrite newer data in WorkersKV, a 30 second progressing window should theoretically mitigate any issue with delivery delay to the eventually-consistent primary datastore. Don't get me wrong, the data model of WorkersKV is a solid one, it's just that you have to be aware of it, and a 30 second window is probably overkill however it's easily run on a cron schedule with enough time to process each batch before the next is due to start.
The second structure to migrate was the Interval Sets used for ASN and country lookups. Whilst I would have loved a fast abstraction layer to do this, the datastore-in-KV layers ended up being unacceptably and costly, so the solution was result was to put ranges into arrays (sharded at the top /8 network) for each IPv4 and IPv6 subnet, and then running a binary search over it. An average binary tree search was about 5-6 integer comparisons which executed quickly, returning the ASN and country for any given IP address.
Fire up the most basic of searches, the binary search with both range support and support for the enormous number space of IPv6.
function binarySearch(arrayOfAddresses, value) {
if (arrayOfAddresses === null || value === null) {
return false;
}
let mid, right;
let left = 0;
right = arrayOfAddresses.length - 1;
value = BigInt(value);
while (left <= right) {
mid = parseInt((left + right) / 2);
if (BigInt(arrayOfAddresses[mid].s) <= value &&
value <= BigInt(arrayOfAddresses[mid].e)) {
return {
'asn': arrayOfAddresses[mid].a,
'country': arrayOfAddresses[mid].c
};
} else if (value < BigInt(arrayOfAddresses[mid].s)) {
right = mid - 1;
} else {
left = mid + 1;
}
}
return false; // not found, return false
}
Once the data structures were done, it was time to learn some proper Javascript. I've only ever coded a bit of Javascript before, and then only to tinker around on the website front end.
After a couple of weeks of on-and-off late evening coding, I was happy enough to let someone else look at it, and they didn’t laugh (or they didn’t tell me that they had). A crudely running API was working with the KV backend. Win!
Performance
Each iteration of code was focused on increasing API performance, such as removing large loops or adding caching.
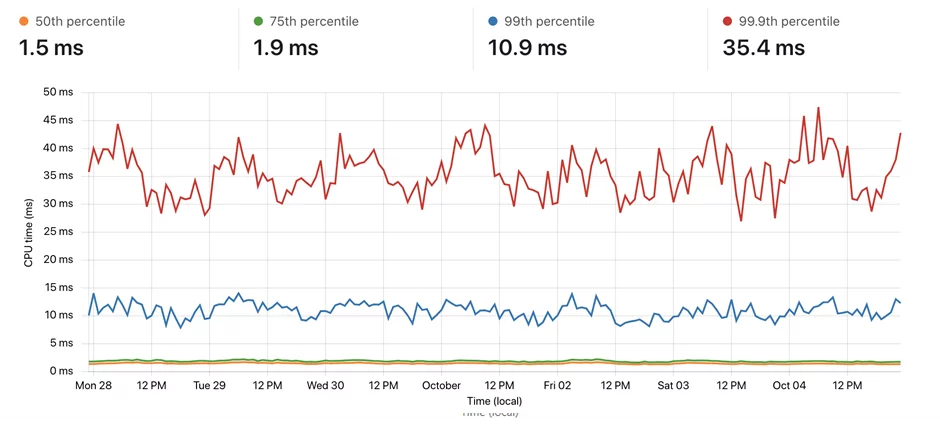
Some of the early testing showed unacceptable levels of performance that put the query time beyond the permitted 50ms.
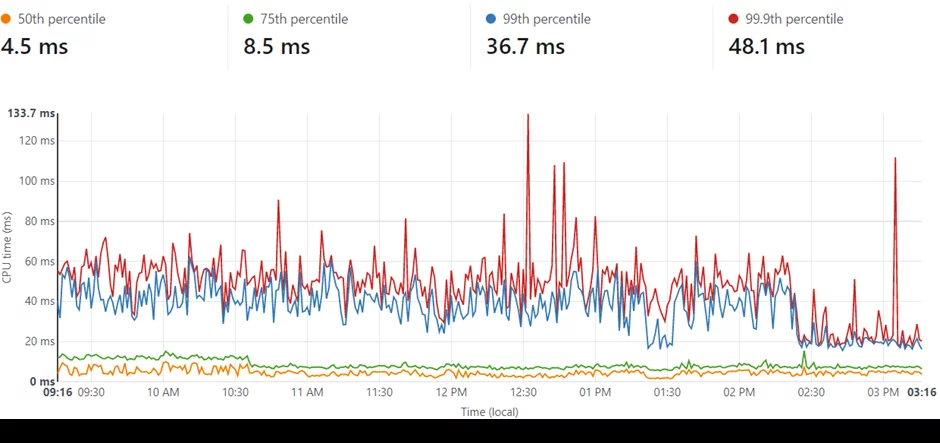
The real gotcha was how I used storing the API configuration in the database. The configuration contains lists of blacklisted IP addresses, domains, and other settings required to process requests. This configuration was being pulled from the database and was then stored as a global variable so that it would persist between requests on each worker, for the life of the worker…. or so I thought.
Testing during development showed this to be the case, so that’s how it was initially deployed. Reality ended up being a very different story that became apparent once Cloudflare deployed WorkersKV analytics.
The metrics showed a huge amount of traffic, numbers that just didn’t match the number of API requests being made. This all pointed to the configuration variable persistence not working as well as intended. Sure, it was cached, but I was unhappy with all the unnecessary latency and network/process traffic that should be removed.
The solution here was obvious, avoid having the configuration in WorkersKV. Easy, you just don't push a configuration into the database, instead you develop a system for updating the configuration in as near real time as possible.
I changed the code to pull the configuration from a json file which is then built with the project on deploy
let globalSettings = await DATASTORE.get('configuration', 'json');
was replaced with
let globalSettings = require('./config.json');
As you can see, the reduction in WorkersKV traffic was significantly smaller, almost embarrassingly so. As the configuration is included in the code, and is available at initialisation, there is no database or cache overhead.
This change, along with the introduction of the LRU cache, resulted in an acceptable latency.
Over a week, we see a steady flow of traffic without errors.
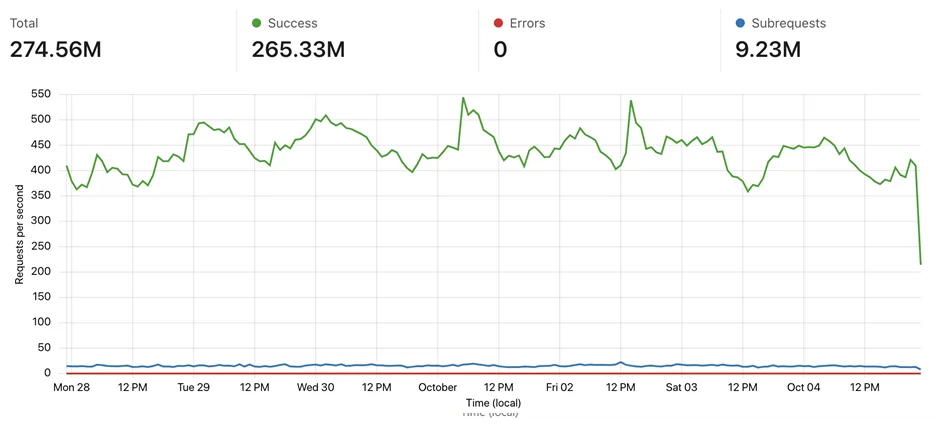
It wasn’t until the API had gone live on Workers until a lot of the metrics started to show the larger picture. If I had to change one thing, it would be to reshard the buckets into 18 bits, or even 20 bits, instead of 16 bits so as to reduce the WorkersKV traffic. The code change is simple enough but it would require MySQL schema and trigger changes. It’s on the list of things to do in the next API version.
Continuous Deployment
This brings me to the next issue, how to continually deploy configuration changes to Workers.
The json configuration file is built by a script when it detects changes in the main configuration stored on the MySQL server. This new file is then signed and pushed to a validation worker that provides an interface to Github.
The code accepts a POST containing the configuration, validates that the json matches the signature in the HTTP header, and then uploads the configuration to Github using their API. To push to Github, you need the SHA256 of the destination file so this worker connects, gets the hash and then includes that hash with the commit.
Once the configuration is committed to the source tree, a Github Action is triggered. Wranger Actions provide the means to control a workflow, and in this case a workflow that checks out the worker source code, including the new configuration, builds it and deploys it via the Cloudflare API
This trigger is controlled by the .github/workflows/main.yaml file, here using Github Secrets to secure the Cloudflare API key required to deploy the new code. Whenever an update to config.js is pushed to Github, the worker code is rebuild and deployed to Workers.
You can read more than Wranger Github Actions at https://github.com/marketplace/actions/deploy-to-cloudflare-workers-with-wrangler
So once it's all put together, we have something where non-API requests are served by the main site, such as search data and submitting spam data, and all API queries being served by Workers in the closest Cloudflare data center to your server.